오브젝트 속성
내부적으로 모텍스트 오브젝트는 돌출 오브젝트를 사용해 그것을 3차원적으로 표현합니다. 텍스트의 3D의 깊이를 정의하려면 돌출 설정을 사용합니다.
돌출한 텍스트의 분할을 정의하려면 이 설정을 사용합니다. 대부분의 경우 값1로 충분할 것입니다. 텍스트 개체를 좀 더 변형하고 싶은 경우(예: 구부리거나 트위스트하는 경우)에 한해 세분화의 값을 좀 더 높은 값으로 설정합니다.
텍스트 박스에 문자를 입력합니다. 엔터 키를 사용하여 새로운 줄을 생성하는 것으로 여러 줄의 문자열을 입력할 수도 있습니다. 문자열은 박스의 바깥을 클릭했을 때 뷰포트의 스플라인 기본 도형에 적용되어 표시됩니다.
Cinema 4D에서는 트루타입과 오픈타입 그리고 포스트스크립 폰트까지 모두 사용할 수 있습니다. 그렇지만 다음과 같은 제한이 따릅니다:
- 매킨토시 (Mac OS X 10.5 이전의 운영체제 시스템에서) : 오픈타입 폰트는 트루타입 어플리케이션에서 수용할 때만 사용할 수 있습니다. 유럽이나 한국 같은 특유의 모든 문자들은 설치만 되어있으면 사용할 수 있습니다.

선택 메뉴에서 폰트 미리보기는 올바른 폰트 선택을 쉽게 해줍니다. 여러분은 화살표 키나 마우스 스크롤 휠을 사용해서 리스트를 스크롤 이동하여 폰트 선택이 가능합니다.
문자열을 왼쪽, 중앙, 오른쪽으로 정렬합니다.

글자간격 조절 설정이 개별 문자에 영향을 주는 반면 다음 3개의 파라미터는 전체 텍스트에 적용하고 이 파라미터들은 부가적으로 사용됩니다.
문자들의 높이를 월드 좌표계로서 정의합니다.
문자간의 간격을 지정합니다.
문자열간의 간격을 지정합니다.

어떤 폰트들은 잘못 디자인되어 엣지가 깨어지는 현상이 발생합니다. Cinema 4D는 이 문제를 해결할 수 없습니다. 항상 최고의 결과를 위해 좋은 품질의 폰트를 사용합니다.
폰트 오브젝트상에 베벨 커맨드를 사용하였을 때 퐁 쉐이딩 탭의 퐁 각도를 20도로 지정하면 3D 폰트에서 좋은 결과를 얻을 수 있습니다.

글자간격 조절(커닝) 설정은 글자에서 텍스트 크기와 간격을 정의할 수 있습니다. 따라서 예를 들어, "A”와 "V” 사이의 공간을 조정하고 싶은 경우(종종 있는 일입니다.), 외부 프로그램을 사용해서 파라미터에 의한 문자 수정을 할 필요가 없게 됩니다. 뷰포트내에서, 모든 수정을 인터렉티브하게 할 수 있습니다.
다음 속성들은 문자 (또는 전체 텍스트)에 대해 수정할 수 있습니다:
- 글자간 간격 조절
- 수평 또는 수직 크기조절 또는 전체 크기조절
- 기준선에서의 높이 (수직 높이) 결과적으로 파라미터의 오른쪽과 같은 작품이 완성됩니다:

3D GUI 표시 옵션을 활성화하면 뷰포트에 다음 핸들들이 표시됩니다:
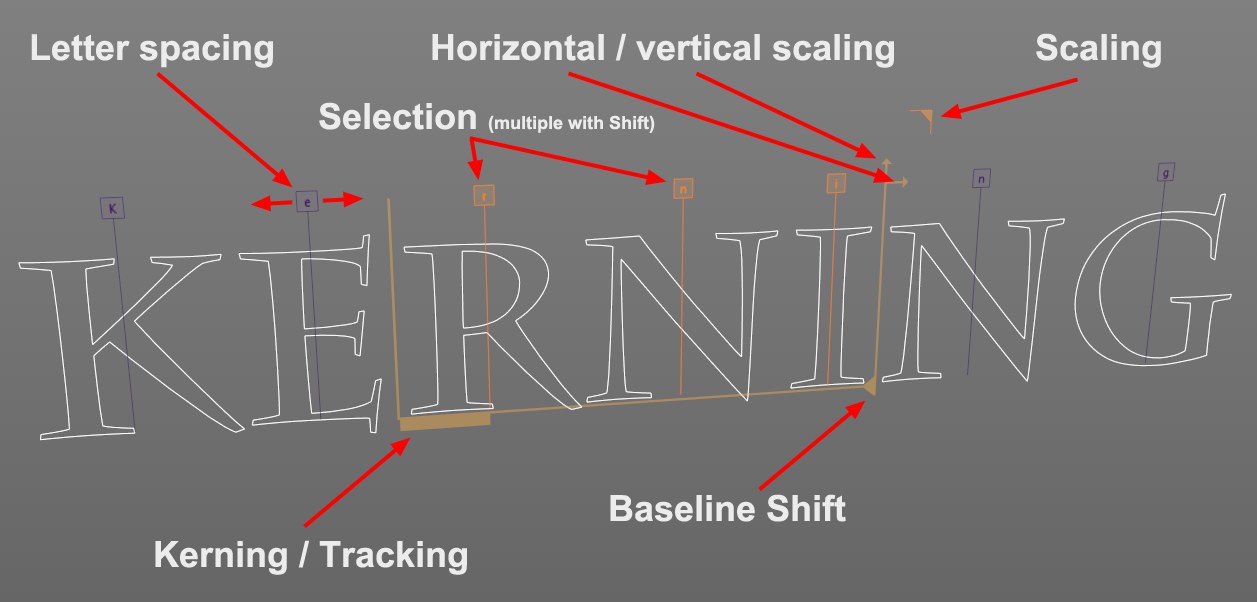 표시된 핸들들은 마우스를 이용해서 선택해서 드래그할 수 있습니다.
표시된 핸들들은 마우스를 이용해서 선택해서 드래그할 수 있습니다.마킹된 해당 핸들이 각각의 문자에 나타나고 이러한 핸들을 드래그하면(선택없이)해당 문자의 왼쪽 공간을 조정할 수 있습니다. 물론 선택 영역을 사용할 수도 있습니다:
- 문자 핸들을 클릭해서 선택합니다.
- 핸들을
Shift + 클릭해서 이 문자와 마지막으로 선택한 문자 사이의 모든 문자를 선ㄴ택합니다. (다른 문자를 클릭하면 선택이 취소됩니다.) 이제 위의 이미지에 마킹된 핸들 중 하나가 움직일 때에는 선택한 문자의 속성(트래킹, 크기조절, 기준선에서의 높이)이 동시에 해결되는 것입니다. (각각 동일한 절대 값)
문자는 텍스트 자체에 관계없이 선택할 수 있고, 선택한 문자에만 영향을 미칩니다. 즉, 5-9 문자를 선택하고 다른 텍스트를 입력하면 5-9 문자에만 작용하게 됩니다.
핸들을 드래그하여 다음 키를 누르면 다음과 같은 효과가 발생합니다.:
-
Shift : 해당 파라미터가 10씩 수정됩니다. -
Cmd/Ctrl : 해당 파라미터가 서로 매우 천천히 수정됩니다.(미세 조정이 용이합니다;Shift 키를 동시에 누르면 파라미터는 하나씩 수정됩니다.)
이 옵션을 사용하여 상호작용적인 3D 핸들을 뷰포트에 표시할 지 여부를 정의합니다 . 텍스트의 글자간격 조절이 끝나면 텍스트 특성을 후작업에서 실수해서 수정하는 일이 없도록 이 옵션을 즉시 해제해둡니다.
해당 핸들을 사용해서 다음 파라미터를 뷰포트에서 상호 조정할 수 있습니다.(위 참조)
이러한 설정 선택 수치는 일반적으로 뷰포트에서 상호 정의하는 것이 가능합니다. (위 참조) 그러나, 이 값은 예를 들어 문자 핸들이 중복될 때 등, 속성 관리자에서 더 쉽게 해결할 수 있는 경우가 있습니다. 두번째 문자를 선택하려면, 시작에 1과 끝에 2를 입력합니다.3~6번째 문자를 선택하려면 2와 6을 입력합니다.
이러한 설정은 반복 XPresso 노드를 사용해서 모든 개별 문자와 그 글자간격 조절 파라미터에 연속해서 액세스할 때에 사용할 수 있습니다.
이러한 설정은 문자에 있는 핸들로 선택하지 않고, 트래킹의 수정을 뷰포트내에서 언제라도 할 수 있다는 예외를 제외하고, Cinema 4D와 기본적으로 동일한 기능 갖고 있습니다. 글자간격 조절 설정 - 다수의 문자가 선택된 경우에는 하나의 핸들만 표시합니다 - 여러 문자에 동시에 적용할 수 있습니다.
이들은 2개 모두 각 문자의 왼쪽 공간을 조정하기 위한 설정입니다.
이러한 설정해서 문자의 수평 비율 및 수직 비율을 개별적으로 조정합니다.
이 값은 문자 전체의 스케일을 정의합니다. (위의 값을 반영)
이 설정에서 문자를 상하로 이동합니다.
이 버튼을 클릭하면 모든 값이 초기값으로 돌아갑니다.
이 버튼을 클릭하면 선택한 모든 문자 값이 초기값으로 돌아갑니다.
이 버튼을 클릭하면 속성 관리자에서 텍스트 필드 내의 모든 문자를 선택합니다.
응용프로그램의 이유로 인해서 글자간격 조절 설정을 보통의 키프레임 애니메이션을 적용할 수 없으므로 주의하세요. 애니메이션은 모든 커닝 설정에 액세스할 수 있는 XPresso경유로 할 수 있습니다. 다음의 프로젝트를 추천합니다:

여기에서는 중간 중간의 포인트들로 스플라인이 세분화될 때 어떤 식으로 세분화될지를 정의할 수 있습니다. 이는 스플라인으로 제네레이터 오브젝트를 만들어줄 때의 세분화의 수에 영향을 줍니다.
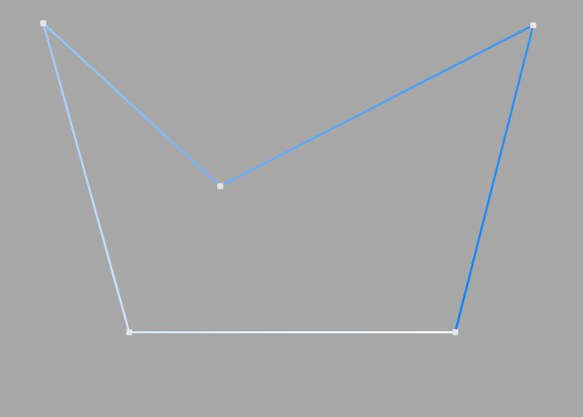
이 보간법은 중간 중간에 포인트를 추가하지 않고 오직 포인트들을 스플라인의 정점에만 배치해주므로 분할수 혹은 분할 각도 박스에 어떤 값도 입력할 수 없습니다. B-스플라인의 경우 포인트들은 스플라인 커브 위에 위치하게 됩니다.

이 보간법은 우선 스플라인 정점 위에 포인트들이 위치합니다. B스플라인의 경우에는 스플라인 커브상의 스플라인 정점들과 가장 가까운 위치에 포인트들이 놓여지게 됩니다. 분할수는 정점들 간의 놓여지는 포인트들의 숫자를 의미합니다. 스플라인상의 곡률이 더 큰 지점에는 포인트들이 서로 더 가깝게 위치하게 됩니다.
이 보간법에서는 분할 각도 박스에 수치를 입력할 수 없으며 포인트의 순서를 바꿔줘도 보간에는 영향을 주지 않습니다.
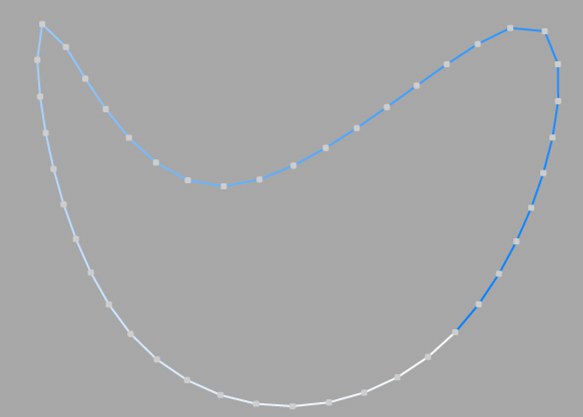
이 보간법은 스플라인을 스플라인 곡률을 따라 측정한 후 두 연속된 포인트 사이의 거리를 균등하게 나눕니다. 두 포인트 중 하나는 항상 정점의 시작점에 위치합니다. 열린 스플라인의 경우에는 나머지 하나의 포인트 역시 끝나는 정점에 위치하게 됩니다. 그 외의 다른 포인트들은 일반적으로는 정점들과 일치하지는 않습니다.
이 보간법에서는 분할 각도 박스에 수치를 입력할 수 없으며 포인트의 순서를 바꿔줘도 보간에는 영향을 주지 않습니다.
열린 스플라인: ((숫자+ 1) * (정점들의 숫자- 1)) + 1
닫힌 스플라인: (숫자+1) * 정점들의 숫자
그러므로 4개의 정점과 분할 수가 2로 설정된 열린 스플라인의 경우에는 ((2+1)*(4-1))+1=10개의 중간 포인트를 가지게 됩니다. 만약 스플라인이 닫혀있는 경우에는 추가로 가상의 정점이 추가되어 중간 포인트의 숫자는 (2+1)*4=12개가 됩니다. 이렇게 가상의 포인트들을 추가함으로써 스플라인을 닫을 경우 더 거칠게 나뉘어지지 않도록 합니다.

이 보간법에서는 커브의 각도 랜덤이 분할 각도 항목에 입력된 값보다 큰 경우에는 항상 중간 포인트들을 설정합니다. 결과적으로 만들어지는 커브의 포인트들은 정점을 지나가게 됩니다. 만약 스플라인이 여러 개의 세그먼트를 가지고 있는 경우에는 분할 각도 값은 각각의 세그먼트에 적용됩니다.
이 최적 보간법은 디폴트 보간법으로 사용되며 렌더링 시에 이 보간법을 적용함으로써 최적의 결과를 얻을 수 있습니다.
세분화는 최적과 매우 유사합니다. 추가적인 중간 포인트들은 중간 세그먼트들이 최대 길이에서 정의해 준 것보다 짧아질 때까지 추가됩니다. 즉 포인트 간격이 최대 길이와 같을 필요는 없습니다. 이 값을 낮춰 줄 경우 퀄리티는 더 좋아지지만 그에 따라 포인트의 수가 늘어남으로써 에디터 뷰에서의 화면 갱신 속도가 느려지는 부작용이 있을 수 있습니다.
이 보간법을 이용하면 디포머가 적용된 텍스트의 렌더링 퀄리티를 획기적으로 향상시킬 수 있습니다. 돌출 오브젝트(캡 탭에서 레귤러 그리드 옵션을 선택되어있어야 함)에서 최대 길이를 폭의 값과 동일하게 설정함으로써 쉐이딩 에러 없이 거의 완벽한 캡과 엣지를 만들어줄 수 있습니다. 글자들과 캡의 세분화는 동일하게 적용되므로 수동으로 일일이 설정해줄 필요는 없습니다.
 선택된 수식 디포머 오브젝트에 적용된 보간법들의 예. 이미지의 오른쪽의 정의된 엣지를 참고하시기 바랍니다.
선택된 수식 디포머 오브젝트에 적용된 보간법들의 예. 이미지의 오른쪽의 정의된 엣지를 참고하시기 바랍니다.왼쪽: 중간 포인트들최적; 오른쪽:세분화;
 왼쪽부터 순서대로: 모두 ,라인 단위, 단어 단위, 문자 단위 인덱스에 컬러 쉐이더가 적용되고 있습니다. (컬러 쉐이더의 채널 설정은 인덱스 비율에서 설정되고 있습니다.)
왼쪽부터 순서대로: 모두 ,라인 단위, 단어 단위, 문자 단위 인덱스에 컬러 쉐이더가 적용되고 있습니다. (컬러 쉐이더의 채널 설정은 인덱스 비율에서 설정되고 있습니다.)모텍스트 오브젝트의 각각의 문자는 내부적으로 넘버링되고 있습니다. 어떤 쉐이더 인덱스 옵션을 선택했는지에 따라 모텍스트 오브젝트의 문자가 연속적으로 넘버링되는지(모든 문자 인덱스) 또는 각각의 행에 대해 0부터 다시 넘버링이 시작되는지(라인 문자 인덱스) 혹은 각각의 단어에 대해 0부터 다시 넘버링이 시작됩니다(단어 문자 인덱스). 그럼 이것은 무엇을 위해서 도움이 되는 것일까요? 인덱스 비율 채널 설정을 가지는 컬러 쉐이더(앞쪽의 Cinema 4D 레퍼런스 설명을 참조하십시오)가 위치를 정하기 위해서 이 넘버링이 사용됩니다. 게다가 내부적인 U-좌표도 이 넘버링의 체제에 따라 스스로의 위치를 정합니다. 항상 0에서 1의 범위를 가지는 이 U-좌표는 다음과 같이 문자에 대해서 할당할 수 있습니다:
텍스트의 최초의 문자로부터 마지막 문자까지.
1 라인마다.
1 단어마다.