Nodes-Verteilung
Dieses Asset bildet die Basis für die Erstellung eigener, auf Nodes basierender Verteilungsfunktionen, mit denen ein MoGraph Klon-Objekt gesteuert werden kann. Ab C4D 2026.1 existiert daran ein separater, fortgeschrittener Modus, der die Nutzung und Verlinkung von Node-Verteilungen erlaubt, um alternative Verteilungsarten zu ermöglichen. Da innerhalb der Nodes-Umgebung z. B. auch der Zugriff auf die Abmessungen der zum Klonen verwendeten Objekte möglich ist, werden dadurch auch gänzlich neue Verteilungen möglich, die sich auch individuell abhängig von der Größe der geklonten Objekte verändern können. Denken Sie z. B. an geklonte Perlen an einer Kette, die trotz zufällig variierter Durchmesser immer mit konstanten Abständen zu den Nachbarn platziert werden können.
 Diese unterschiedlich großen Bücher wurden über eine Nodes-Verteilung automatisch so platziert, dass es keine Abstände dazwischen gibt und alle Bücher auf einer Ebene stehen. Dies ist möglich durch die Auswertung der Bounding Box jedes verwendeten Objekts, was so bei den klassischen Verteilungsmodi eines Klon-Objekts nicht möglich wäre.
Diese unterschiedlich großen Bücher wurden über eine Nodes-Verteilung automatisch so platziert, dass es keine Abstände dazwischen gibt und alle Bücher auf einer Ebene stehen. Dies ist möglich durch die Auswertung der Bounding Box jedes verwendeten Objekts, was so bei den klassischen Verteilungsmodi eines Klon-Objekts nicht möglich wäre.
Übersicht
Eine Nodes-Verteilung erzeugen
Eine Nodes-Verteilung kann zwar auch manuell über den Asset Browser in die Szene integriert werden, z. B. indem diese von dort direkt in den Objekt-Manager gezogen wird. Da die Nodes-Verteilung jedoch hauptsächlich für die Kombination mit einem Klon-Objekt konzipiert ist, gibt es eine noch bequemere Option:
An einem Klon-Objekt schalten Sie dafür einfach in den "fortgeschrittenen" Betriebsmodus um und betätigen dann dort die Erzeugen-Schaltfläche. Dadurch wird automatisch eine neue Nodes-Verteilung im Objekt-Manager erzeugt, direkt mit dem Klon-Objekt verlinkt und der Node-Editor zum Bearbeiten der Verteilungskapsel geöffnet. Ansonsten kann der Node-Editor für die Verteilung auch jederzeit durch einen Doppelklick auf die Nodes-Verteilung im Objekt-Manager geöffnet werden.
Eine Verteilung selbst konfigurieren
Am Ausgang einer Nodes-Verteilung wird die Verteilung ausgegeben, durch die ein Klon-Objekt die Anzahl, Platzierung und z. B. Färbung der Klone umsetzen kann. Eine Verteilung besteht aus einer Sammlung verschiedener Arrays, die alle so viele Einträge haben müssen, wie Klone erzeugt werden sollen. Für das Zusammenstellen der Verteilung wird in der Regel ein Container zusammensetzen-Node verwendet, an dem die entsprechenden Array-Eingänge mit verschiedenen Datentypen angelegt werden müssen. Die folgende Abbildung zeigt dazu die verschiedenen Arrays und deren Datentypen, die zum Zusammenstellen der Verteilung benötigt werden.
Dabei müssen nicht immer alle Arrays definiert und an die Verteilung übergeben werden. Zu den Arrays, die jedoch immer definiert werden sollten, gehören:
- Matrix: Die Matrizen beschreiben die Positionen, Rotationen und Größen der Klone.
- Index: Diese Zahlenwerte stehen für die individuelle Nummer jedes Klones, beginnend mit 0 für den ersten Klon.
- Verhältnis: Ein Zahlenwert zwischen 0 und 1, der die Reihenfolge der Klone wiedergibt. Der erste Klon erhält immer den Wert 0 und der letzte den Wert 1.
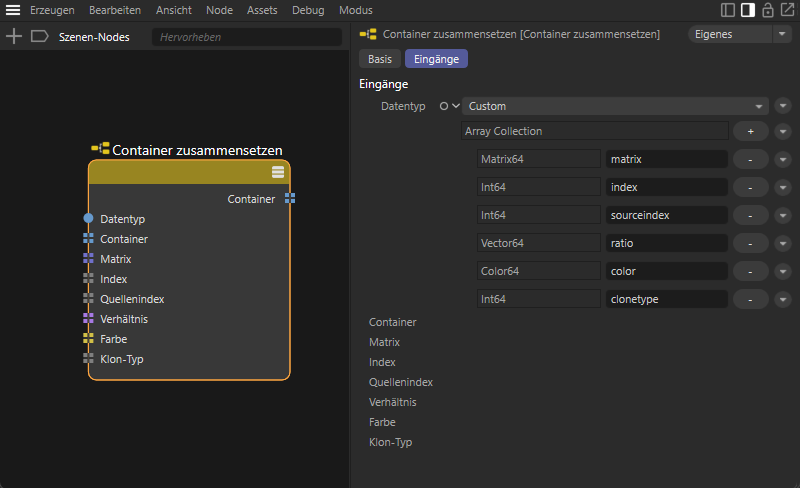 Hier sind die verschiedenen Arrays und deren Datentypen zu erkennen, die an einem Container zusammensetzen-Node vorhanden sein sollten, um alle Eigenschaften einer Verteilung definieren zu können.
Hier sind die verschiedenen Arrays und deren Datentypen zu erkennen, die an einem Container zusammensetzen-Node vorhanden sein sollten, um alle Eigenschaften einer Verteilung definieren zu können.
Dieser Vorgang lässt sich folgendermaßen vereinfachen:
1. Rufen Sie innerhalb der Nodes-Verteilung im Node-Editor einen Container zusammensetzen-Node auf.
2. Erzeugen Sie eine Oberflächen Blau-Noise-Verteilung im Node-Editor.
3. Ziehen Sie eine Verbindung zwischen dem Verteilung-Ausgang der Oberflächen Blau-Noise-Verteilung und dem Datentyp-Eingang am Container zusammensetzen-Node. Dadurch wird automatisch eine Typumwandlung auf dieser Verbindung eingefügt, und verschiedene neue Array-Eingänge erscheinen am Container zusammensetzen-Node. Dabei handelt es sich um alle korrekten Eigenschaften und Datentypen, die auch durch die Nodes-Verteilung erwartet werden. Die Blau-Noise Verteilung- und Typ von-Nodes können nun direkt wieder gelöscht werden.
4. Um diese Arbeitsschritte für die Erstellung zukünftiger Nodes-Verteilungen überspringen zu können, selektieren Sie den Container zusammensetzen-Node und öffnen für diesen im Attribute-Manager das Voreinstellungsmenü. Wählen Sie dort Preset speichern... aus und tragen Sie für Name z. B. Verteilung Container zusammensetzen ein. Nach der Bestätigung über die OK-Schaltfläche können Sie zukünftig diese Einstellung direkt für einen neu erzeugten Container zusammensetzen-Node in dem Voreinstellungsmenü auswählen (siehe auch folgende Abbildung).
Standardmäßig werden derartige Voreinstellungen für Nodes direkt im Asset Browser unter Nodes > Presets > Node Presets abgelegt und können von dort auch direkt in den Node-Editor gezogen werden, um sofort einen passend konfigurierten Node erzeugen zu lassen.
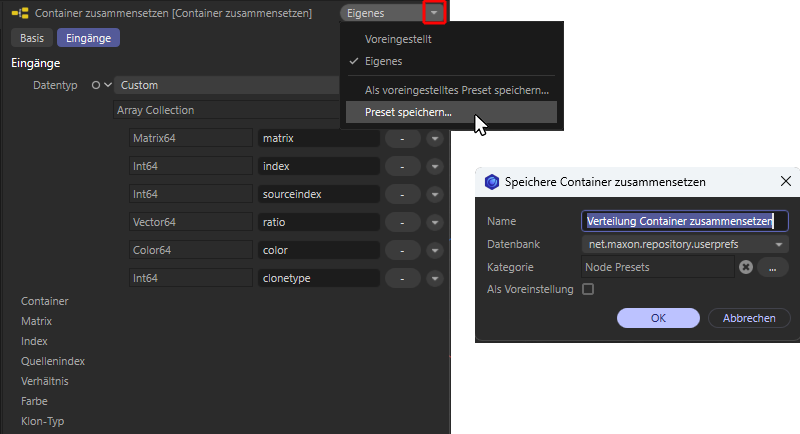 Speichern des modifizierten Container zusammensetzen-Nodes als Voreinstellung zum schnellen Aufrufen bei häufiger Nutzung.
Speichern des modifizierten Container zusammensetzen-Nodes als Voreinstellung zum schnellen Aufrufen bei häufiger Nutzung.
Das nachfolgende Video fasst die beschriebenen Arbeitsschritte noch einmal zusammen und endet mit dem direkten Aufruf eines passend konfigurierten Nodes aus den Presets des Asset Browsers.
Die einzelnen Arrays der Verteilung stehen dabei für die hier beschriebenen Eigenschaften der Verteilung. Beachten Sie zudem, dass alle Arrays innerhalb der Verteilung die identische Anzahl an Einträgen enthalten müssen, die der gewünschten Anzahl an erzeugten Kopien entsprechen sollte.
Nachfolgend besprechen wir noch einige Strategien zum Erzeugen eigener Verteilungen:
Strategien zum Erstellen eigener Verteilungen
Nicht alle Eigenschaften einer Verteilung müssen manuell erstellt werden, wir betrachten daher hier einige Strategien, um eigene Verteilungen zu erstellen.
Bekannte Verteilungen modifizieren
Oft existieren bereits Verteilungen, die sich nur in speziellen Eigenschaften von dem unterscheiden, was als individueller Verteilung erzeugt werden soll. Was liegt also näher, als eine der bereits existierenden Verteilungen als Basis für eigene Modifikationen zu nutzen?
Für dieses Beispiel greifen wir daher auf die Linear-Verteilung zurück und ziehen diese in den Nodes-Bereich der Verteilung-Kapsel hinein (siehe folgende Abbildung). Die Verteilung-Kapsel wurde in diesem Fall durch Umschalten des Verteilungstyp-Menüs eines neuen Klon-Objekts auf Fortgeschritten erzeugt und ist daher automatisch bereits mit dem Klon-Objekt verknüpft.
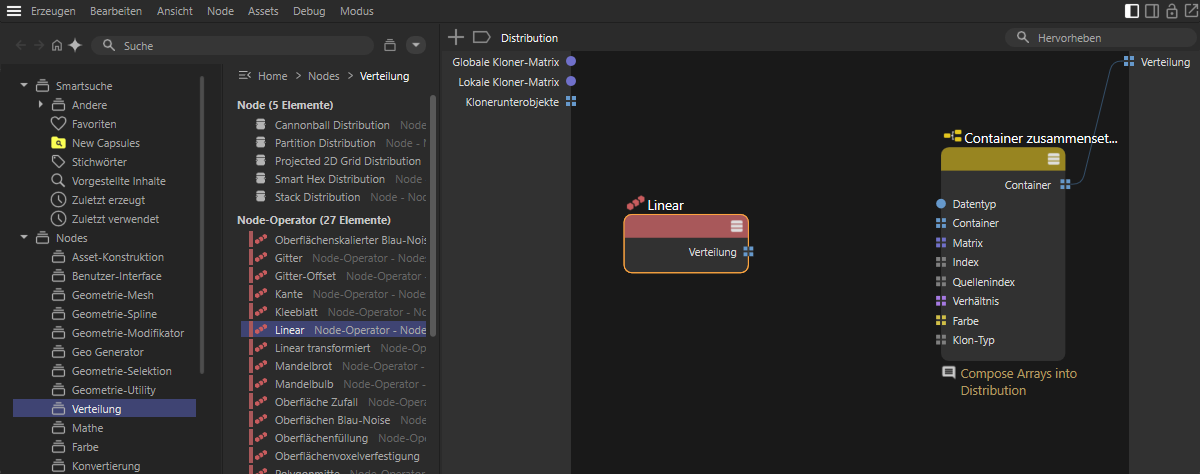 Oft kann eine bereits integrierte Verteilung modifiziert werden, um die gewünschte neue Verteilung zu erstellen. Hier wird eine Linear-Verteilung als Basis verwendet.
Oft kann eine bereits integrierte Verteilung modifiziert werden, um die gewünschte neue Verteilung zu erstellen. Hier wird eine Linear-Verteilung als Basis verwendet.
Wie in der folgenden Abbildung festgehalten, lässt sich die vorgegebene Verteilung mit einem Container zerlegen-Node in die einzelnen Arrays zerlegen, die dann an die entsprechenden Eingänge eines Container zusammensetzen-Nodes geleitet werden können, der seine Ausgabe an die Verteilung der Kapsel leitet. Damit ist bereits eine funktionsfähige Verteilung-Kapsel definiert, die jedoch noch über die Einstellungen des Linear-Node im Node-Editor konfiguriert werden muss.
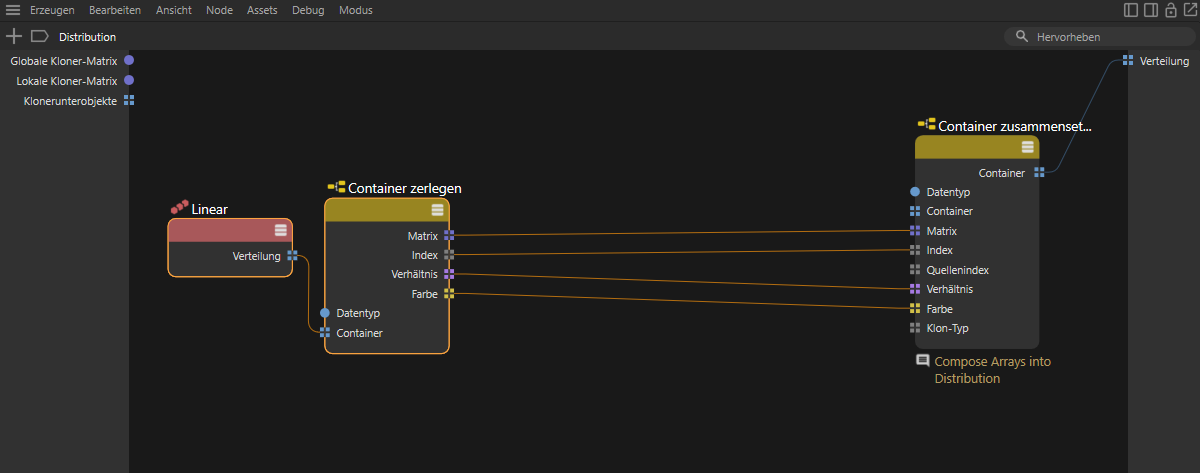 Auflösen und neues Zuweisen der linearen Verteilung.
Auflösen und neues Zuweisen der linearen Verteilung.
Einer der Kernparameter jeder Verteilung ist sicherlich die Angabe der Anzahl der zu erzeugenden Objektkopien. Wir leiten daher nun den Anzahl-Parameter des Linear-Nodes an die Eingabeseite der Kapsel. Dazu fügen wir zunächst einen Anzahl-Port am Linear-Node hinzu indem wir einen Ctrl-Klick auf da Kreissymbol des Anzahl-Parameters im Attribute-Manager ausführen. Anschließend ziehen wir eine Verbindung von diesem Port zu einem leeren Bereich des Node-Editors und lassen die Verbindung dort durch Lösen der Maustaste fallen. Es öffnet sich ein Kontextmenü, in dem wir über den Eintrag Neuen Eingang hinzufügen einen entsprechenden Werteingang an der Kapsel erzeugen lassen, der automatisch mit dem Anzahl-Eingang des Linear-Nodes verbunden wird (siehe folgende Abbildung).
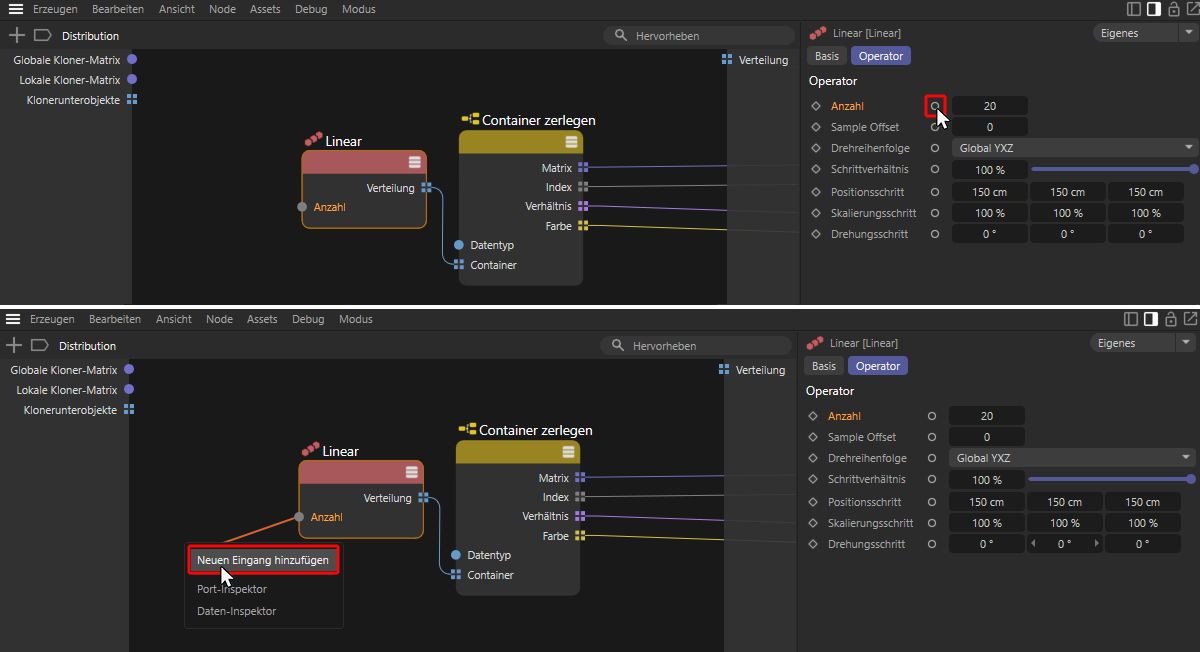 Auswahl eines Node-Parameters für die Eingabe an der Verteilung-Kapsel.
Auswahl eines Node-Parameters für die Eingabe an der Verteilung-Kapsel.
Derart herausgeführte oder manuell an der Eingangsseite der Kapsel erzeugte Eingänge erscheinen automatisch auch in den Eingaben des Klon-Objekts, so wie es die folgende Abbildung zeigt. Dazu muss nur die kleine Pfeil-Schaltfläche vor dem Verteilung-Verlinkungsfeld aufgeklappt werden. In der Eingabe-Rubrik darunter sind dann die Eingangswerte der Verteilung zu finden. Dies ermöglicht die bequeme Bedienung der Nodes-Verteilung, ohne dafür im Node-Editor arbeiten zu müssen.
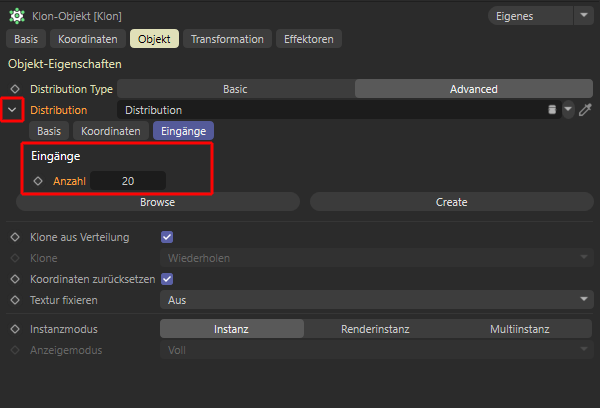 Eingabemöglichkeit für herausgeführte Kapsel-Paramter direkt am Klon-Objekt.
Eingabemöglichkeit für herausgeführte Kapsel-Paramter direkt am Klon-Objekt.
Um nun Kopie für Kopie in die Berechnung z. B. der Positionen für die erzeugten Klone eingreifen zu können, benötigen wir eine Schleifenstruktur innerhalb der Schaltung. Dies bedeutet, dass wir nacheinander die Daten der erzeugten Klone berechnen und am Ende zu einem Array zusammensetzen können. Dazu bietet sich an, mit einem Sammlung iterieren-Node z. B. die Matrizen der Klone einzeln ausgeben zu lassen und diese Informationen anschließend wieder über einen Sammlung zusammensetzen-Node zusammenzufügen. Die folgende Abbildung zeigt, wie diese Nodes in der Schaltung verwendet werden können.
Beachten Sie dabei auch die Nummerierung in der Abbildung, die die Reihenfolge der Node-Verbindungen andeutet. Diese Reihenfolge stellt sicher, dass die Datentypen an den Nodes automatisch korrekt umgeschaltet werden und wir uns darum nicht manuell kümmern müssen. Zwischen den Sammlung iterieren-/Sammlung zusammensetzen-Nodes könnte nun die gewünschte Berechnung z. B. der Klon-Positionen eingefügt werden.
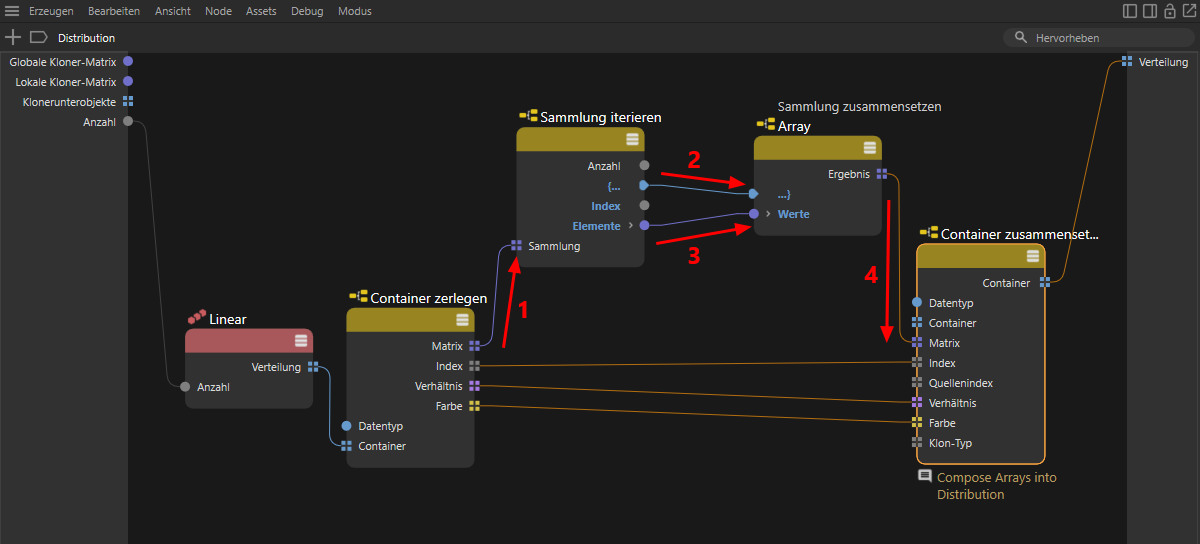 Option zur Erzeugung einer Schleifenstruktur zwischen einem Sammlung iterieren- und einem Sammlung zusammensetzen-Node.
Option zur Erzeugung einer Schleifenstruktur zwischen einem Sammlung iterieren- und einem Sammlung zusammensetzen-Node.
In der Verteilung soll nun davon ausgegangen werden, dass nur ein Objekt unter dem Klon-Objekt eingruppiert wurde. Dessen maximale Abmessungen in X-, Y- und Z-Richtung sollen ausgewertet werden, um daraus automatische Abstände zwischen den zu platzierenden Kopien zu errechnen. Dafür steht uns der Eingang für die Unterobjekte am Klon-Objekt an der Kapsel zur Verfügung, den wir mit einem neuen Container zerlegen-Node aufschlüsseln können. Eine der so offengelegten Informationen betrifft die Bounding Boxes, also die maximalen Abmessungen der Objekte unter dem Klon-Objekt. Wir lassen nur das erste Objekt unter dem Klon-Objekt auslesen, verwenden also mit dem Bounding Box-Array einen Element erhalten-Node mit dem Index 0.
Die so ausgelesene Bounding Box wird durch zwei Vektoren beschrieben, die wir über einen weiteren Container zerlegen-Node auch einzeln auslesen können (siehe nachfolgende Abbildung). Der Vektor am Ausgang _0 steht dabei für die kleinsten Positionswerte einer Umquader-Ecke, der Vektor am Ausgang _1 steht für die maximalen Koordinaten einer Umquader Ecke. Bei der Beschreibung des Klon-Unterobjekte-Eingangs erhalten Sie weitere Erläuterungen dazu.
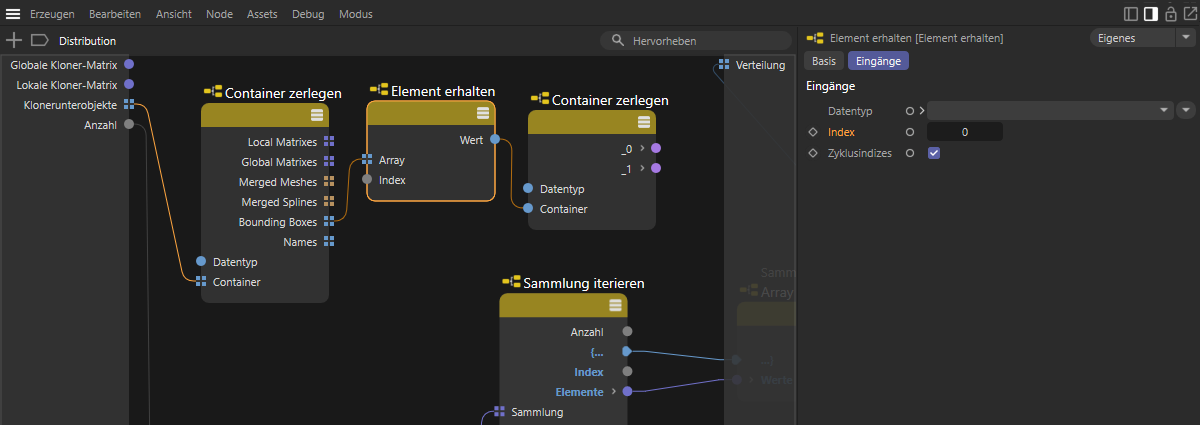 Auslesen der Bounding Box für das erste Objekt unter dem Klon-Objekt.
Auslesen der Bounding Box für das erste Objekt unter dem Klon-Objekt.
Durch Subtraktion des Vektors _0 vom Vektor _1 erhalten wir einen Ergebnis-Vektor, der mit seinen drei Komponenten die maximalen Abmessungen in X-, Y- und Z-Richtung des geklonten Objektsystems angibt. Multiplizieren wir nun noch diese Werte mit der Nummer des aktuell berechneten Klons (siehe Index-Wert am Sammlung iterieren-Node), können wir die Klon-Positionen exakt so berechnen, dass die Objektkopien passgenau platziert werden. Die folgende Abbildung stellt die beiden ergänzten Mathe-Nodes zum Subtrahieren und Multiplizieren selektiert im oberen Teil des Graphen dar. Beachten Sie dabei, dass für diese Nodes der Datentyp jeweils manuell auf Vektor umgeschaltet werden muss, damit es hier zu keiner unerwünschten Umrechnung der Werte kommt.
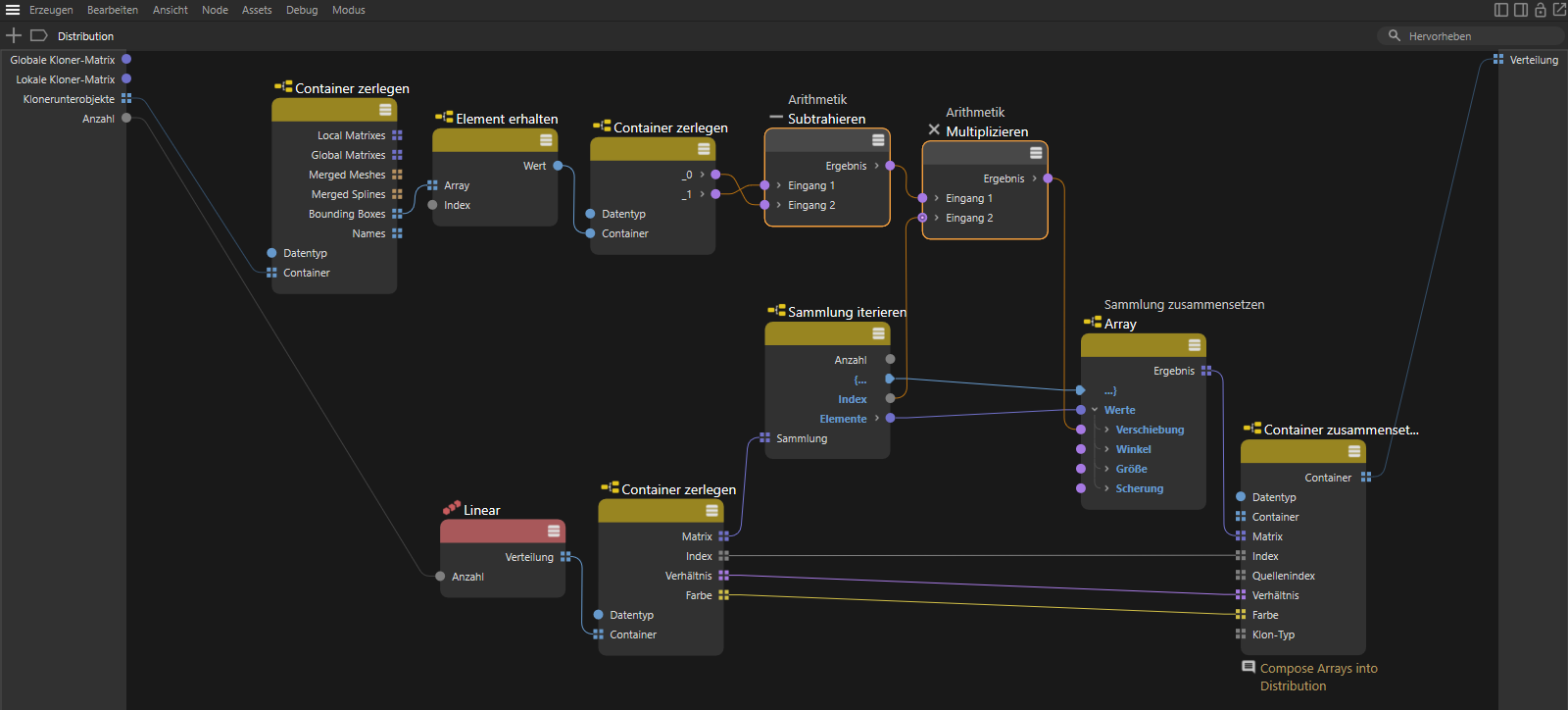 Die ergänzten Mathe-Nodes berechnen die maximalen Abmessungen des ersten Objekts unter dem Klon-Objekt und durch Multiplikation mit dem fortlaufenden Index-Wert die daraus resultierenden Positionen der Klone.
Die ergänzten Mathe-Nodes berechnen die maximalen Abmessungen des ersten Objekts unter dem Klon-Objekt und durch Multiplikation mit dem fortlaufenden Index-Wert die daraus resultierenden Positionen der Klone.
Um die Verteilung nun noch individueller steuern zu können, ergänzen wir noch drei Wert-Regler an der Eingangsseite der Kapsel, um getrennt für die X-, Y- und Z-Richtung angeben zu können, wie stark dort die Bounding Box ausgewertet werden soll. Dazu führen wir einen Rechtsklick in den linken, abgedunkelten Eingangsbereich der Kapsel aus und wählen dann Eingang hinzufügen > Fließkomma aus. Wiederholen Sie dies noch zwei Mal, um letztlich drei neue Eingänge an der Kapsel für Fließkomma-Werte zu erhalten. Durch einen Doppelklick auf die Namen dieser Eingänge lassen sich neue Namen dafür vergeben. Wir entscheiden uns hier für die Namen X-Offset, Y-Offset und Z-Offset.
Durch einen Rechtsklick in den Eingangsbereich der Kapsel rufen wir schließlich noch Resource bearbeiten... auf, um den Resource-Editor zu öffnen. Dort können dann in der linken Liste die Eingänge so per Drag&Drop umsortiert werden, wie Sie dem Nutzer innerhalb der Klon-Objekt-Einstellungen angezeigt werden sollen, also z. B. mit dem Anzahl-Wert zu oberst, gefolgt von den drei neuen Offset-Werten. Im mittleren Teil des Resource-Editors können Sie nun noch den Standardwert, die Minimal- und Maximalwerte, sowie einen optionalen Schieberegler für das Interface der drei Offset-Werte konfigurieren. Die folgende Abbildung zeigt einen Vorschlag für die Konfiguration am Beispiel des X-Offset-Werts. Der Resource-Editor kann nach getaner Arbeit einfach geschlossen werden.
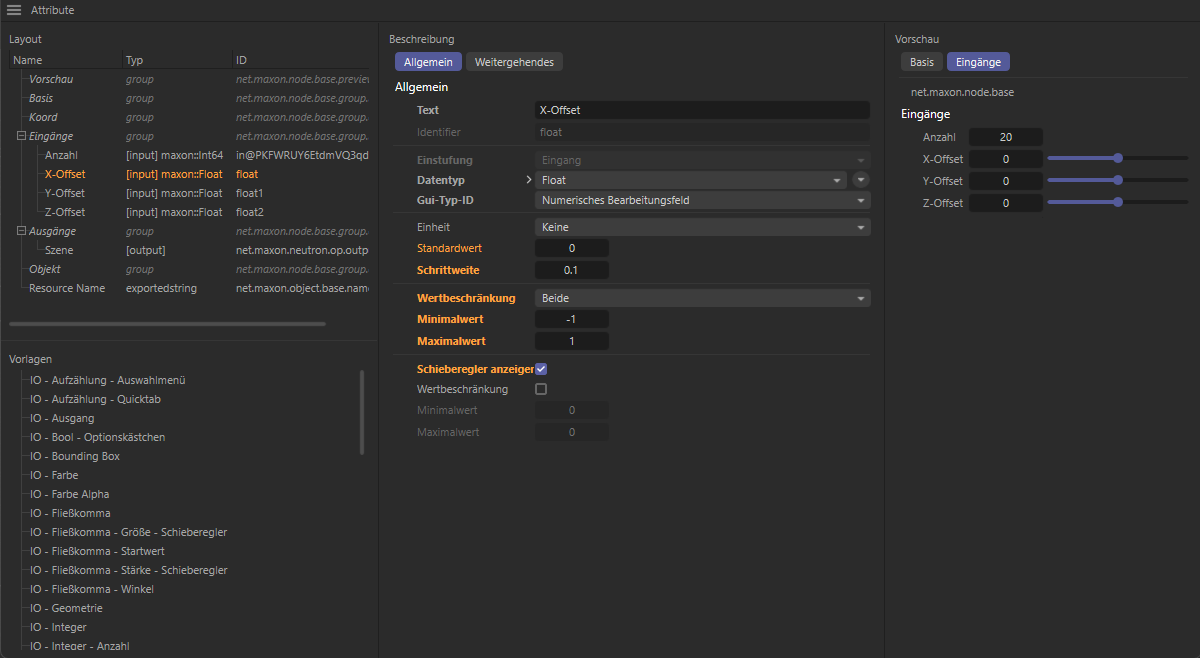 Konfiguration der neuen Offset-Eingänge bezüglich der dort zugelassenen Wertbereiche und der Aktivierung eines Schiebereglers im Resource-Editors.
Konfiguration der neuen Offset-Eingänge bezüglich der dort zugelassenen Wertbereiche und der Aktivierung eines Schiebereglers im Resource-Editors.
Weitergehende Beschreibungen zum Resource-Editor und wie Datentypen und Eingabemöglichkeiten darüber konfiguriert werden können, finden Sie auf dieser Seite zu den Benutzerdaten im Node-Editor.
Wenn wir nun doch diese drei Offset-Einzelwerte mit einem 3D-Vektor erzeugen-Node zusammenfassen lassen und den Ergebnisvektor dann mit unseren berechneten Klon-Positionen multiplizieren (dabei wieder an den Datentyp Vektor denken), erhalten wir eine praktische Verteilung zum Aufstapeln von gleich großen Objekten oder z. B. zur Erstellen von Treppen. Die folgende Abbildung zeigt die fertig Schaltung.
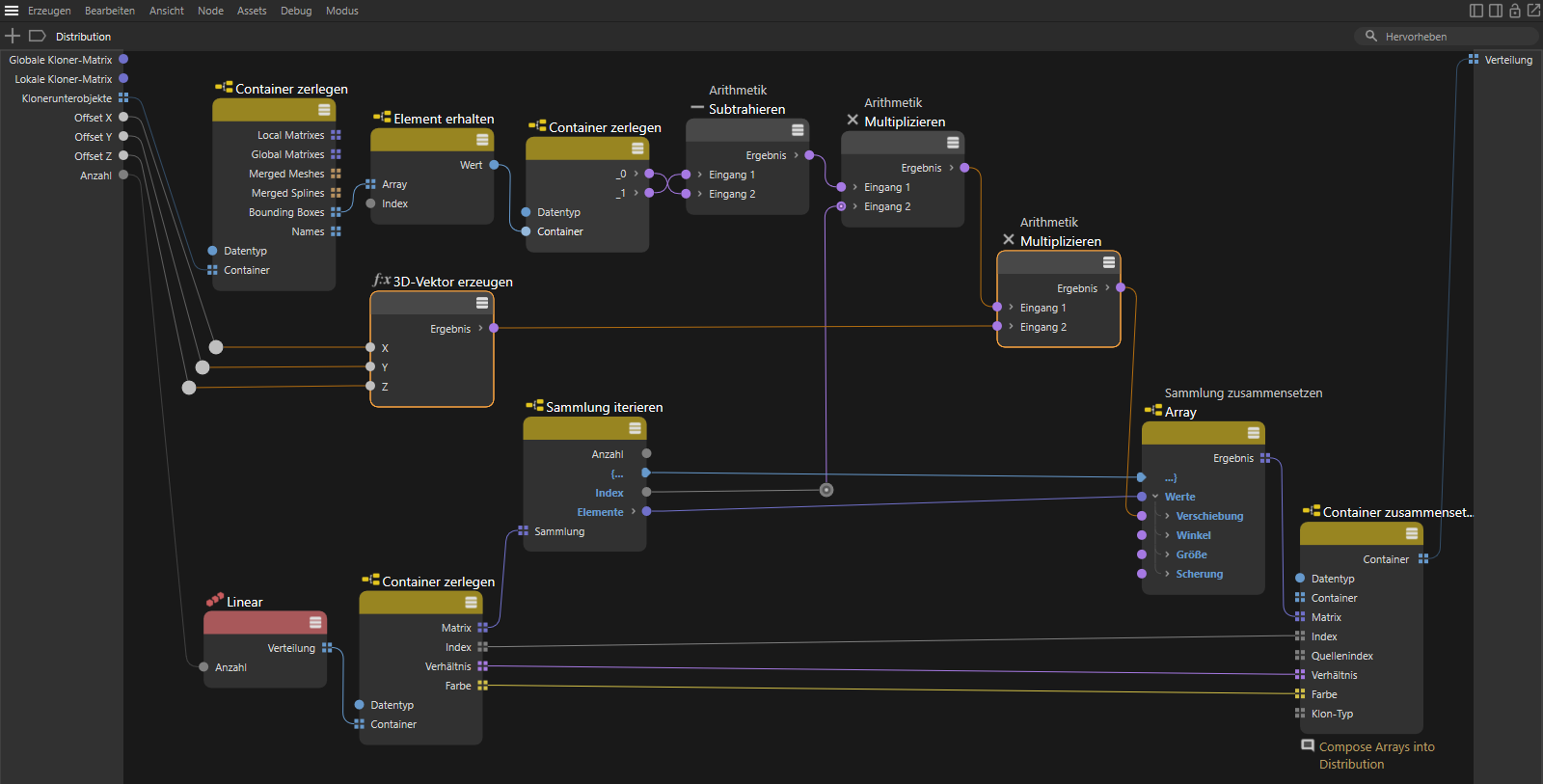 Multiplikation der neuen Offset-Eingänge mit den berechneten Verschiebungswerten für die Klone.
Multiplikation der neuen Offset-Eingänge mit den berechneten Verschiebungswerten für die Klone.

Verteilungen manuell konfigurieren
Neben der im vorherigen Abschnitt vorgestellten Manipulation von über Verteilung-Nodes vorberechneter Daten können wir natürlich auch alles selbst individuell berechnen lassen. Dazu bietet sich oft ein Bereich-Node als Basis an, der eine vorgegebene Anzahl an Werten nacheinander ausgibt. Wenn man für dessen Anfang-Wert 0 und für dessen Ende-Wert die gewünschte Anzahl von Kopien verwendet, hat man damit bereits einen perfekten Rahmen für die Berechnung z. B. von Positionswerten. Die folgende Abbildung stellt so ein Setup exemplarisch dar.
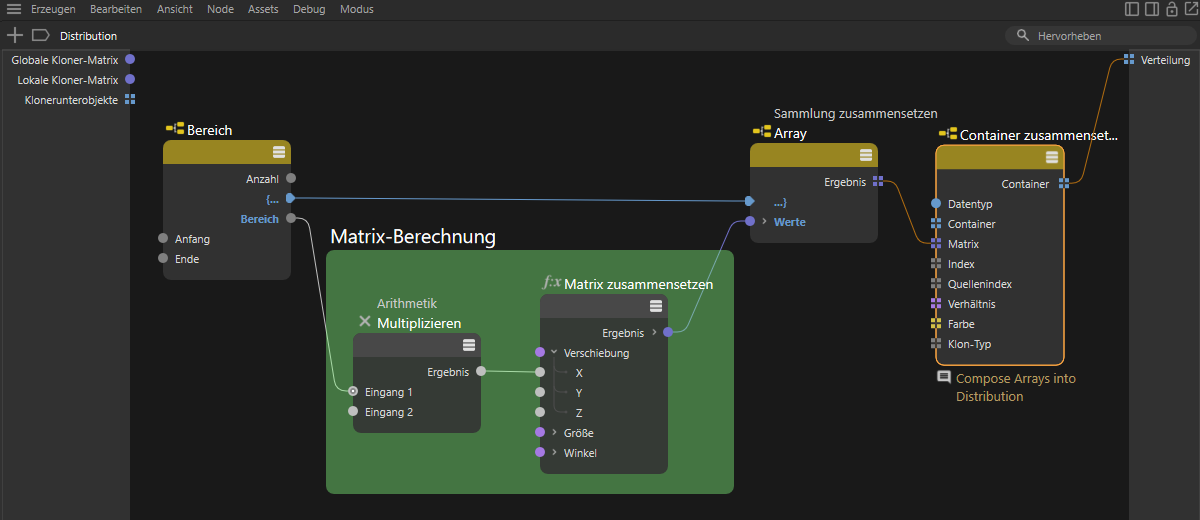 Ein Bereich-Node gibt nacheinander die gewünschten Indexnummern der Klone aus. Der grün hinterlegte Bereich steht stellvertretend für die individuelle Berechnung von Positionen, Rotationen oder Größen aller Klone in Abhängigkeit von der gerade am Bereich-Node zur Verfügung gestellten Bereich-Ausgabe. Über einen Sammlung zusammensetzen-Node können diese Einzelergebnisse zu einem Array zusammengefügt werden, das dann als Matrix-Array an der Verteilung verwendet wird.
Ein Bereich-Node gibt nacheinander die gewünschten Indexnummern der Klone aus. Der grün hinterlegte Bereich steht stellvertretend für die individuelle Berechnung von Positionen, Rotationen oder Größen aller Klone in Abhängigkeit von der gerade am Bereich-Node zur Verfügung gestellten Bereich-Ausgabe. Über einen Sammlung zusammensetzen-Node können diese Einzelergebnisse zu einem Array zusammengefügt werden, das dann als Matrix-Array an der Verteilung verwendet wird.
Auch bei dieser Art von Node-Schaltung steht am Ende wieder ein Sammlung zusammensetzen-Node, der die einzelnen Berechnungsergebnisse Stück für Stück zu einem Array zusammensetzt, das dann als Matrix-Array an einen Container zusammensetzen-Node übergeben werden kann. Wir kennen dieses Prinzip bereits aus dem vorherigen Abschnitt.
Der Datentyp des Sammlung zusammensetzen-Nodes muss hierbei manuell auf Array <Matrix> konfiguriert werden.
 Schrittweise Konfiguration des gewünschten Datentyps an einem Sammlung zusammensetzen-Node. Hier soll ein Array für Matrizen zusammengestellt werden. Dazu wird zuerst die Array-Struktur ausgewählt (links zu sehen) und anschließend das kleine Pfeilsymbol links neben dem Datentyp aufgeklappt. Dadurch werden weitere Einträge des Datentyps sichtbar. In unserem Fall der gerade ausgewählte Array-Datentyp und der dafür standardmäßig verwendete Fließkomma-Datentyp. Über die kleine Pfeiltaste rechts daneben lassen wir diesen Float-Datentyp durch einen Matrix-Datentyp ersetzen.
Schrittweise Konfiguration des gewünschten Datentyps an einem Sammlung zusammensetzen-Node. Hier soll ein Array für Matrizen zusammengestellt werden. Dazu wird zuerst die Array-Struktur ausgewählt (links zu sehen) und anschließend das kleine Pfeilsymbol links neben dem Datentyp aufgeklappt. Dadurch werden weitere Einträge des Datentyps sichtbar. In unserem Fall der gerade ausgewählte Array-Datentyp und der dafür standardmäßig verwendete Fließkomma-Datentyp. Über die kleine Pfeiltaste rechts daneben lassen wir diesen Float-Datentyp durch einen Matrix-Datentyp ersetzen.
Wichtig bei dieser Art Schaltung ist zudem die zusätzliche Verbindung der {... bzw ...} Ports am Bereich- und am Sammlung zusammensetzen-Node, damit diese als eine Einheit berechnet werden. Das Ergebnis-Array am Sammlung zusammensetzen-Node ist schließlich erst dann komplett für die Übergabe an den Container zusammensetzen-Node bereit, wenn der Bereich-Node seinen kompletten Wertebereich zwischen Anfang und Ende-1 durchlaufen hat.
Bei dieser Art von Verteilungsberechnung bietet es sich oft an, den Ende-Wert für den Bereich-Node als Eingang an der Nodes-Verteilung zur Verfügung zu stellen, um so bequem direkt am Klon-Objekt die gewünschte Anzahl an Objektkopien einstellen zu können. Dazu ziehen Sie eine Verbindung vom Ende-Eingang des Bereich-Nodes in einen leeren Bereich des Node-Editors und lassen dort die Verbindung durch Lösen der linken Maustaste einfach fallen. Es erscheint ein Kontextmenü, in dem Sie Neuen Eingang hinzufügen auswählen. Der dadurch neu erzeugte Port wird automatisch mit dem entsprechenden Eingang des Nodes verbunden und kann durch einen Doppelklick auf dessen Namen auch direkt z. B. zu "Klonanzahl" umbenannt werden. Dieser Begriff taucht dann so auch direkt als Eingabemöglichkeit am Klon-Objekt auf und ermöglicht die komfortable Bedienung der Verteilung, ohne dafür den Node-Editor öffnen zu müssen.
Die Ausgaben am Bereich-Node können auch direkt für zwei weitere Elemente einer Verteilung verwendet werden, nämlich für das Verhältnis und den Index. Für Index kann direkt der Ergebnis-Ausgang verwendet werden, während sich der Ratio-Wert jedes Klons automatisch aus dem Verhältnis von Ergebnis/Anzahlergibt, so wie es die folgende Abbildung zeigt.
Bei der Verhältnis-Berechnung sind nur gewisse Sicherheitsvorkehrungen zu treffen, damit z. B. eine Division durch den Wert 0 nicht möglich wird. Wir setzen dafür einen Begrenzen-Node ein, an dem sich die geforderten Unter- und Obergrenzen eines Werts vorgeben lassen. So lässt sich durch dessen Maximum-Wert z. B. auch eine Obergrenze für die maximal zu erzeugende Klon-Anzahl setzen, falls gewünscht. Ansonsten verwenden Sie dort einfach nur einen sehr großen Wert. Zudem muss der Anzahl-Wert des Bereich-Nodes noch um 1 reduziert werden, damit wir tatsächlich durch die Division der aktuellen Klon-Nummer durch die Gesamtzahl der Klone Werte zwischen 0 und 1 erhalten. Wir realisieren dies durch einen arithmetischen Mathe-Node.
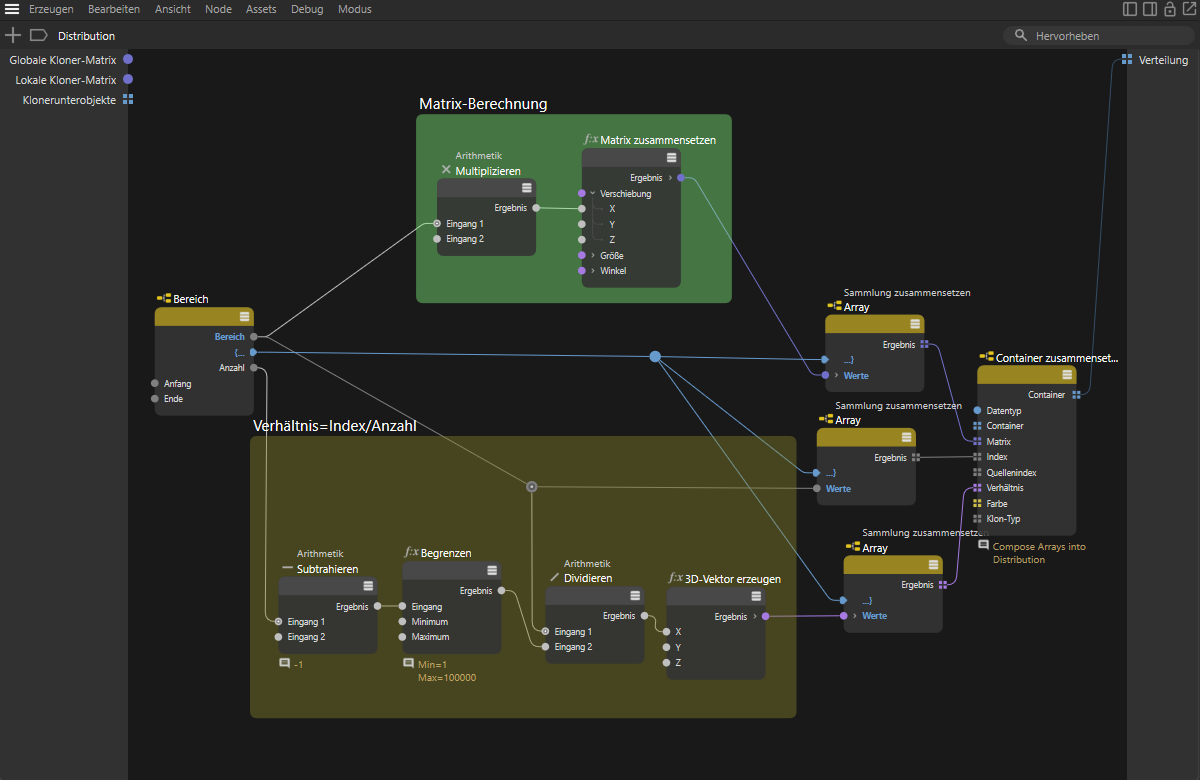 Die Ausgänge des Bereich-Nodes können auch direkt zur Berechnung den Index- und des Verhältnis-Arrays der Verteilung genutzt werden.
Die Ausgänge des Bereich-Nodes können auch direkt zur Berechnung den Index- und des Verhältnis-Arrays der Verteilung genutzt werden.
Achten Sie auch auf die richtigen Datentypen der Sammlung zusammensetzen-Nodes. Das Index-Array muss vom Typ Integer sein und das Verhältnis-Array sollte ein Vektor-Array sein. Entsprechend schalten wir hier einen Vektor zusammensetzen-Node vor, so wie es oben in dem gelblich unterlegten Schaltungsteil zu sehen ist.
Am bequemsten ist es, wenn Sie das Umschalten des richtigen Datentyps dem Node selbst überlassen. Damit dies funktioniert, stellen Sie einfach nur sicher, dass der eingeleitete Wert den richtigen Datentyp hat, die Verhältnis-Werte also z. B. als Vektoren vorliegen und die Daten zur Positionierung und Ausrichtung der Klone als Matrizen.
Ähnlich einfach können schließlich auch die Farbwerte berechnet werden, z. B. um einen beliebigen Farbverlauf zwischen dem ersten und dem letzten Klon umzusetzen. Auch dafür eignet sich das durch die Division bereits berechnete Verhältnis, denn dieser Wert kann an einem Mischen-Node zum Überblenden zweier Farbwerte verwendet werden. Der Datentyp des Mischen-Nodes muss dafür auf Color oder ColorA umgeschaltet werden. Die beiden Farbeingänge des Nodes können dann z. B. auch direkt als Eingänge an der Kapsel angeboten werden, damit der Nutzer diese selbst individuell wählen kann. Verfahren Sie dabei so, wie wir es bereits beim Ende-Eingang des Bereich-Nodes vorgeführt haben, um entsprechende Eingang-Ports an der Kapsel zu erzeugen.
Am unteren Ende dieser Seite finden Sie auch die fertige Szene zum direkten Download.
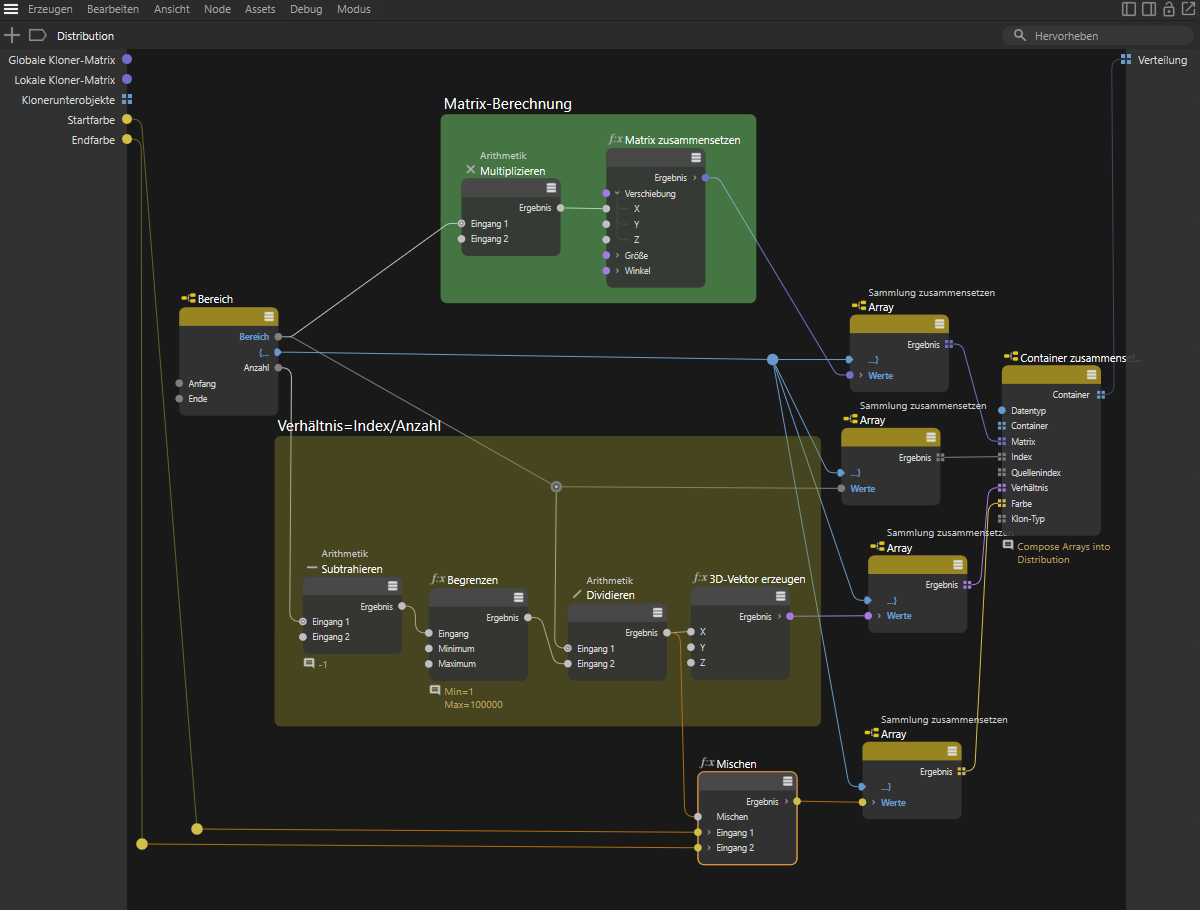 Der Verhältnis-Wert der Klone kann z. B. auch zur Farbberechnung verwendet werden. Hier wird er an einem Mischen-Node als Mischen-Wert von zwei Farben genutzt. Die Farben für den ersten und den letzten Klon können direkt als Eingänge an dem Node herausgeführt werden, damit der Nutzer diese bequem vorgeben kann, ohne die Nodes der Kapsel editieren zu müssen.
Der Verhältnis-Wert der Klone kann z. B. auch zur Farbberechnung verwendet werden. Hier wird er an einem Mischen-Node als Mischen-Wert von zwei Farben genutzt. Die Farben für den ersten und den letzten Klon können direkt als Eingänge an dem Node herausgeführt werden, damit der Nutzer diese bequem vorgeben kann, ohne die Nodes der Kapsel editieren zu müssen.